prometheus性能优化之RecordingRule
问题发现
客户的k8s环境在查看grafana时发现某些图表无法展示2天的数据,如下:
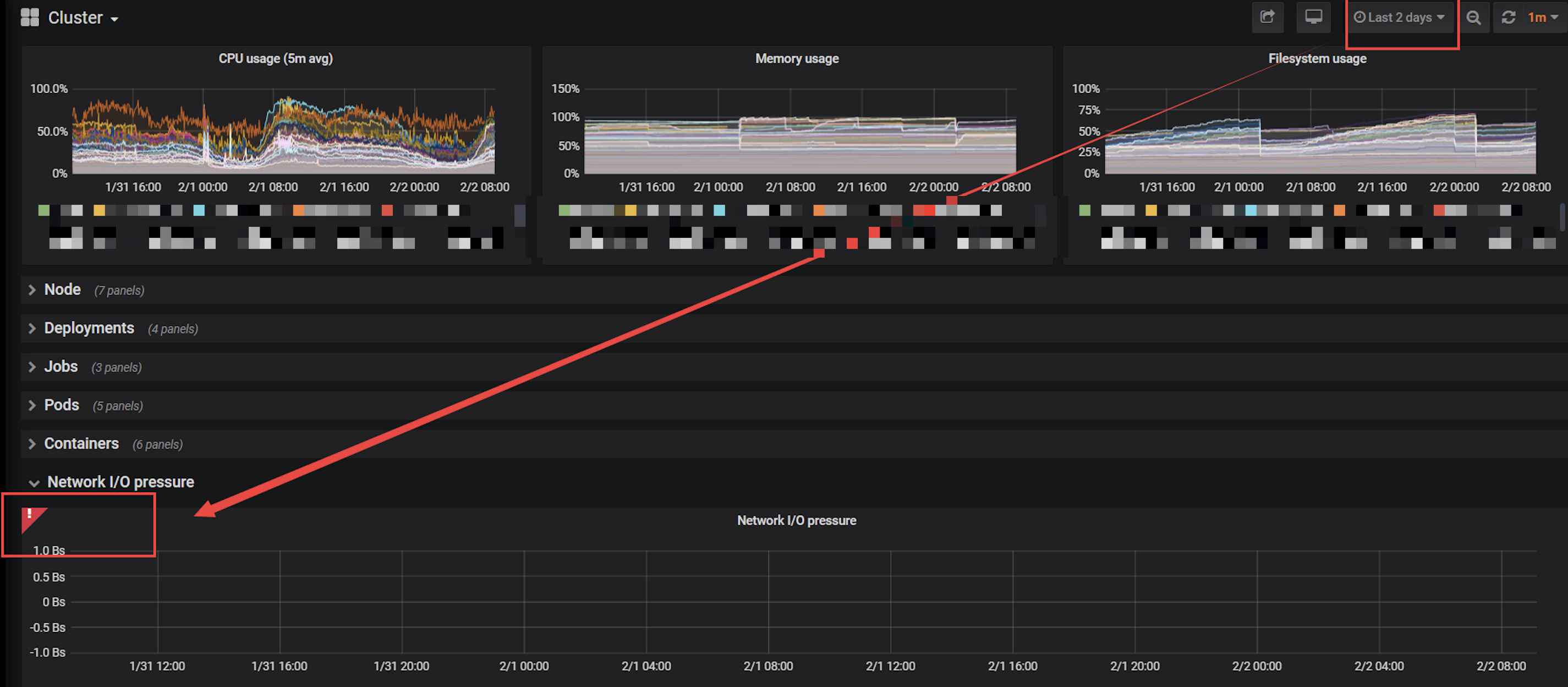
环境
- rancher-v2.3.6
- 监控版本0.0.7
排查过程
首先先查看这个图表使用了哪些表达式
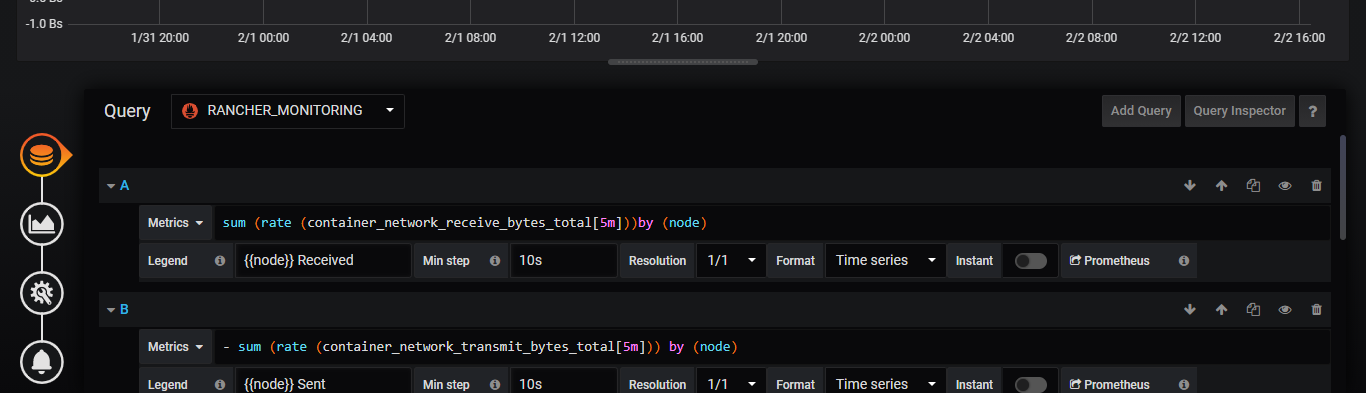
接着带着这个表达式,到prometheus查看
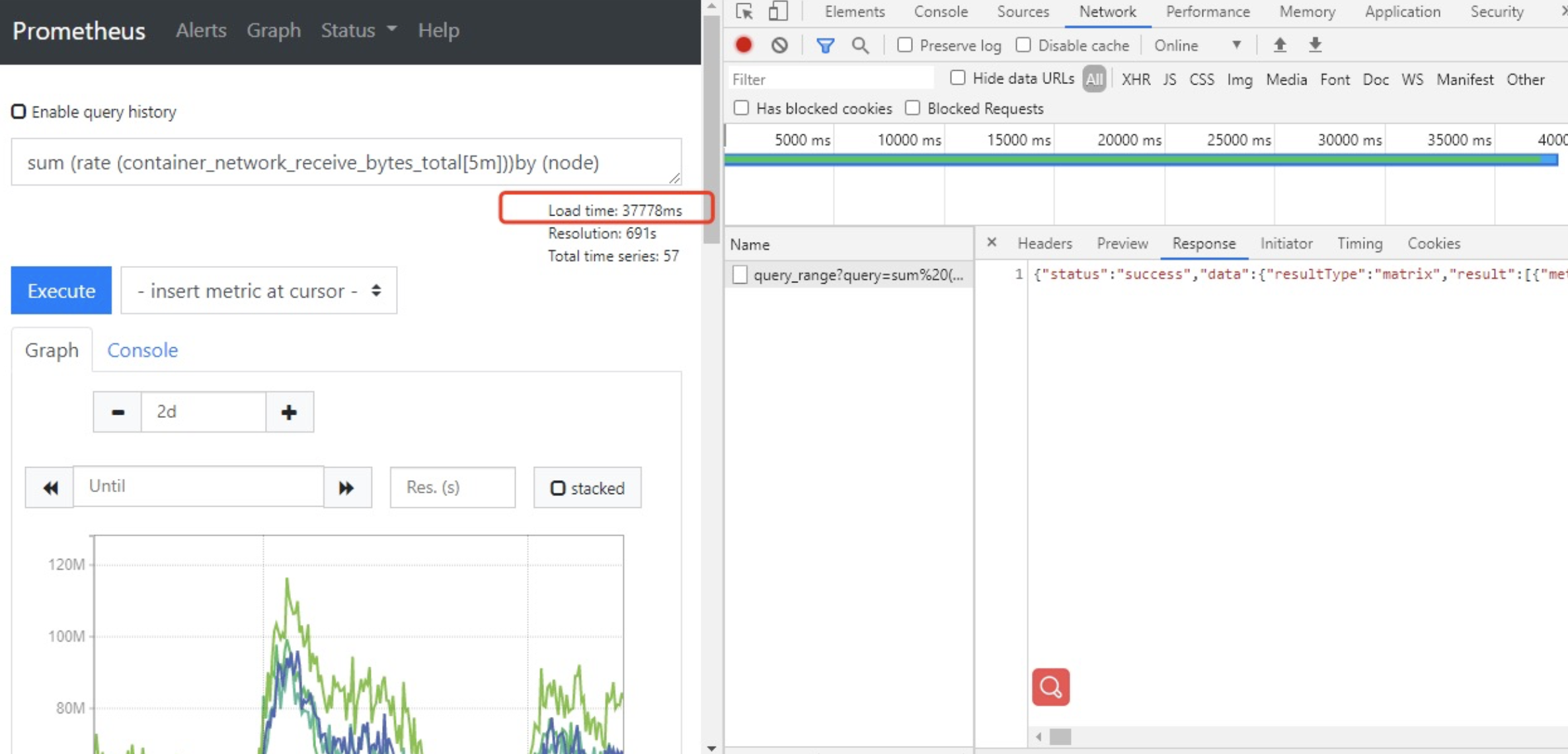
可以看到,查询这个表达式花费了37秒的时间,而这仅仅是其中一条表达式,由此可以得知grafana查看不到数据的原因是在获取prometheus的数据超时了
随着业务的扩大,prometheus中监控的数据会越来越多,查询的频率也在不断的增加,这就会导致当数据量达到一定程度时会影响prometheus查询的性能,尤其是如果有大量的表达式计算指标数据时,就会导致promql查询超时
根据客户反映,prometheus设置了30天的保存时间,集群比较大,数据指标也比较多,所以导致这个grafana使用表达式去查询数据指标的时候,使用了大量的时间去执行这个计算,最终导致返回超时
优化
首先想到的是清理旧数据,让数据获取少一点,但是这个效果并不明显
既然是因为表达式计算的过程花费的时间长,那么我们可不可以事先将该表达式计算的结果存储下来,后面查询的时候就不用再进行二次计算,直接获取对应的指标数据呢?
当然是可以的,prometheus提供了这样的一种方法:Recording Rule
Recording Rule:Recording Rule可以预先计算经常需要或计算量大的表达式,并将其结果保存为一组新的时间序列。这样,查询预先计算的结果通常比每次需要原始表达式都要快得多。这对于仪表板特别有用,仪表板每次刷新时都需要重复查询相同的表达式。
步骤
- 首先获取grafana中的表达式
1 | sum (rate (container_network_receive_bytes_total[5m]))by (node) |
- 编写对应的prometheus rule 配置文件
1 | apiVersion: monitoring.coreos.com/v1 |
其中:
spec.groups.name.rules.expr:需要计算的表达式spec.groups.name.rules.record:为这个表达式重新命名
运行该文件
1 | kubectl apply -f prometheus-custom-rule.yaml |
- 重建prometheus加载新的规则
- prometheus中查看rule是否生效
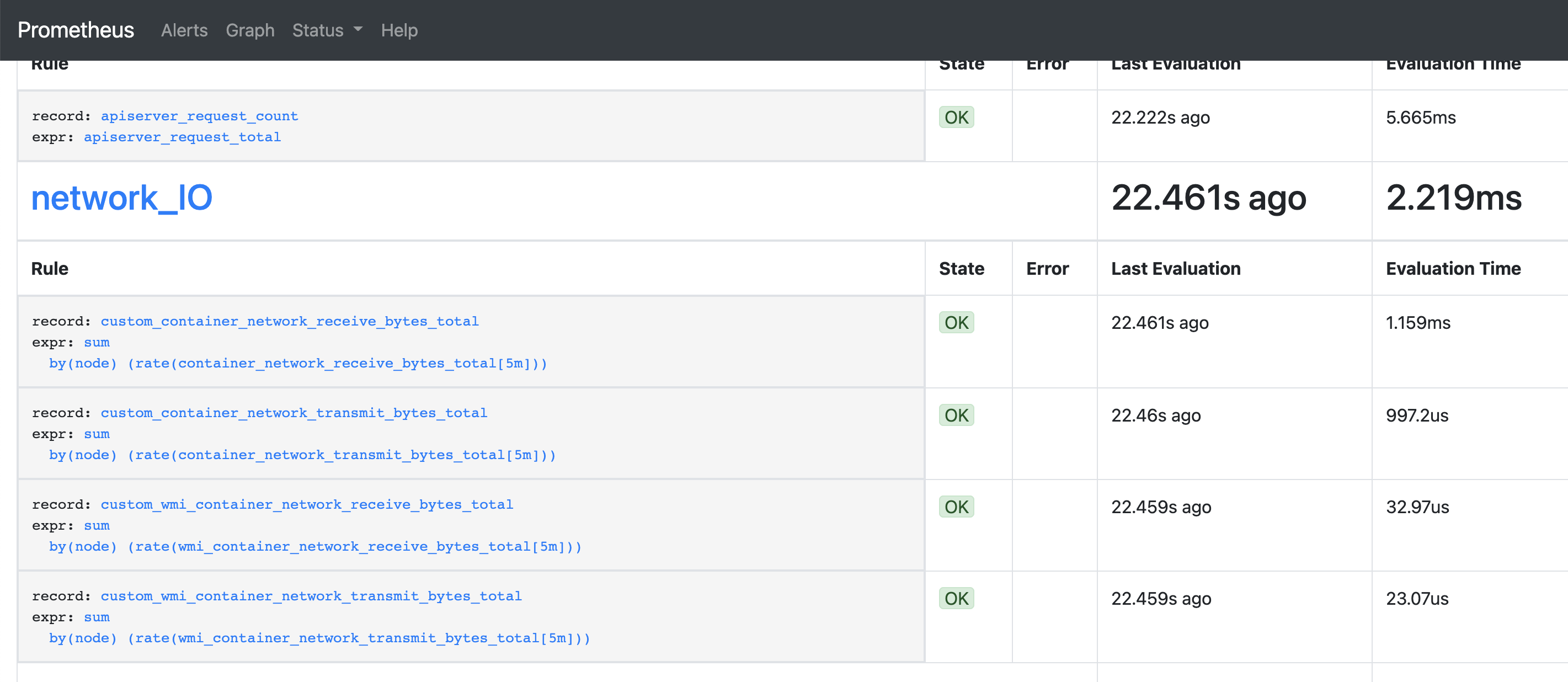
使用新的record去查询,可以看到查询的时间花费了142ms,时间立刻缩短了
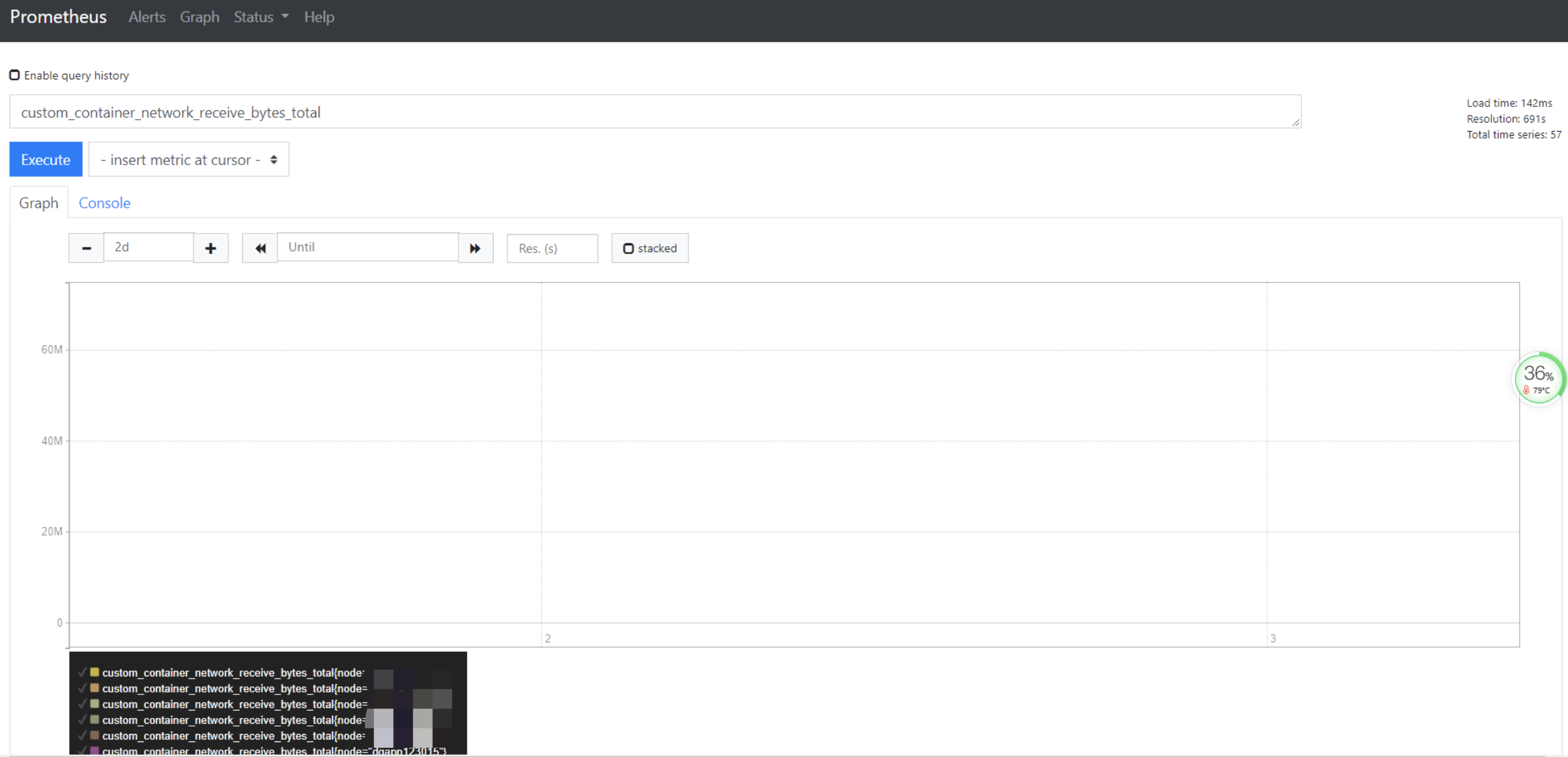
- 接着我们到grafana中修改图表的表达式,将之前旧的表达式修改为新的指标
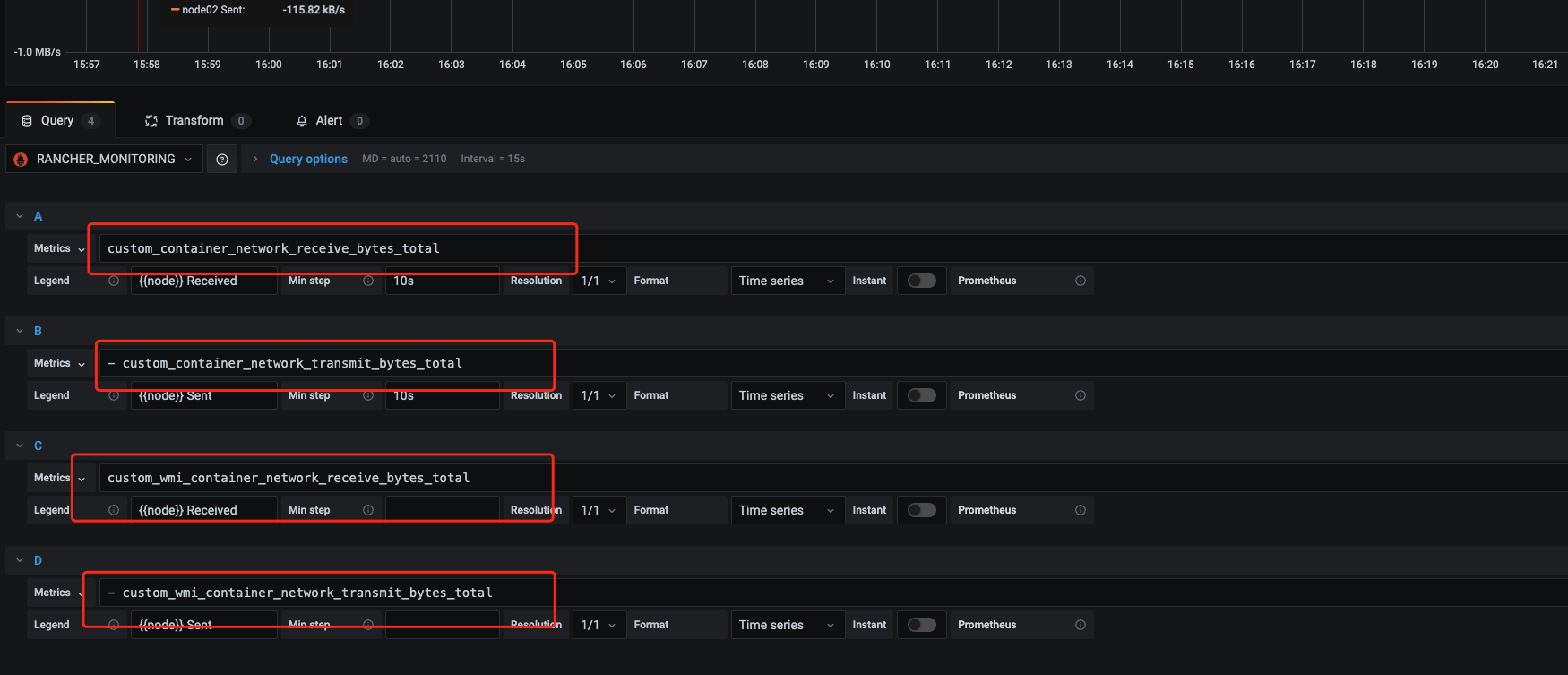
- 导出一个新的json文件
- 重新导入到grafana中
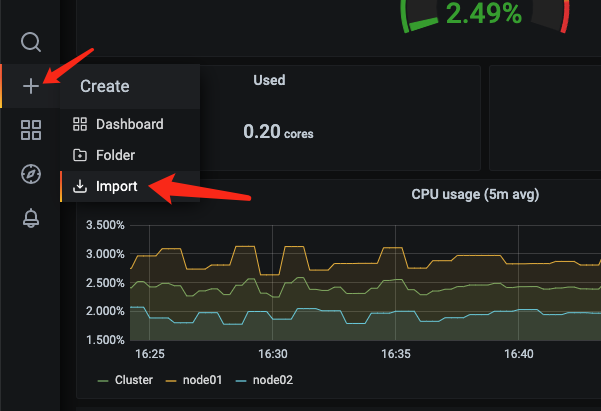
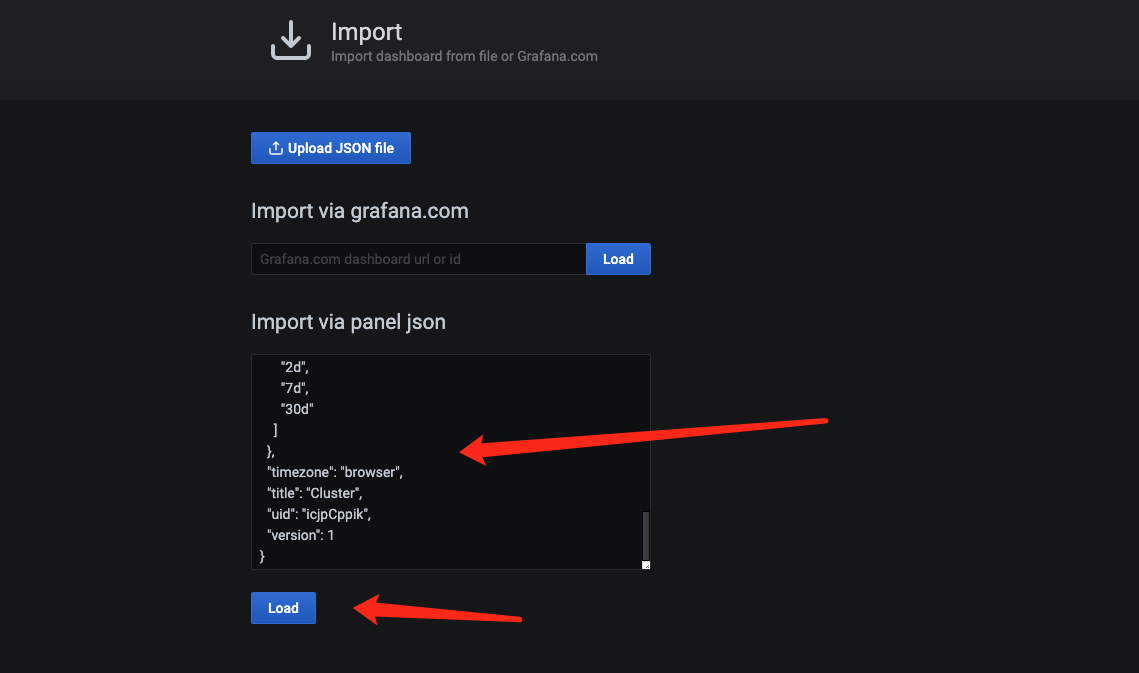
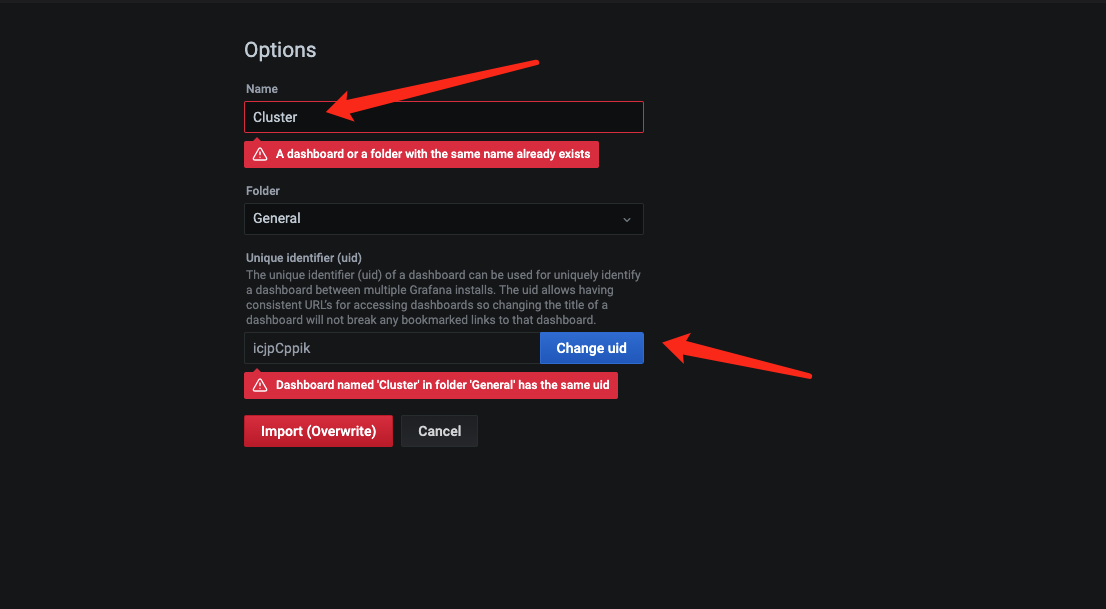
查看数据,可以看到数据已经加载上去了
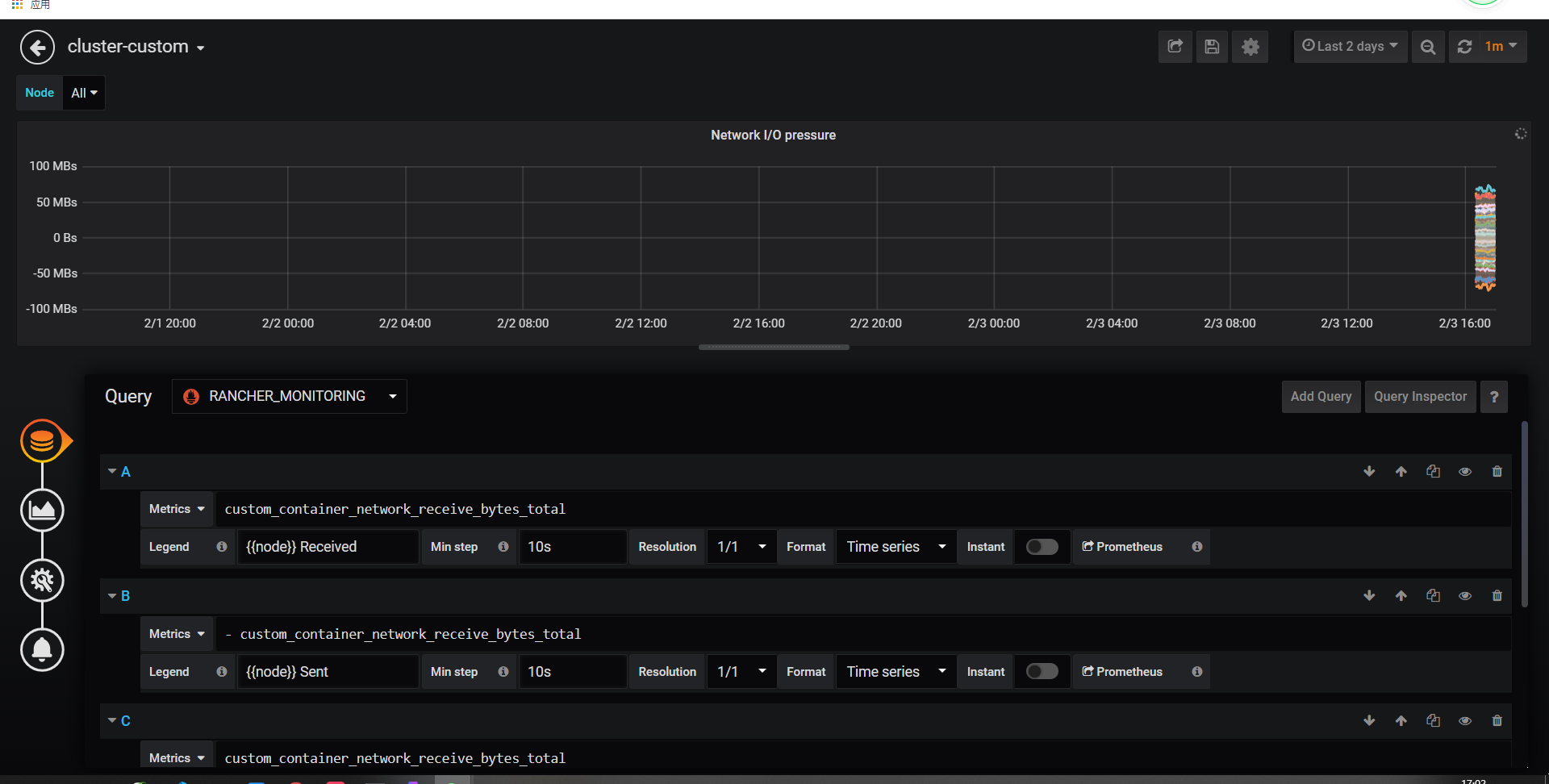
结论
使用prometheus Recording rule可以简化监控指标,加速外部服务访问prometheus的速度,当如果有许多固定的查询规则,并且需要进行多种计算处理,例如Grafana相关的图表展示,则可以事先定义好对应的Recording rule,提高监控效率。