k8s学习(29):使用Helm部署Prometheus
Prometheus架构
Prometheus是一个非常优秀的监控工具。准确的说,应该是监控方案。Prometheus提供数据收集、存储、处理、可视化和告警一套完整的解决方案

- Prometheus Server:负责数据采集和存储,并提供一套灵活的查询语言(PromQL)供用户使用
- Exporter:Exporter负责收集目标对象(host、container)的性能数据,并通过HTTP接口供Prometheus Server获取
- Grafana:可视化组件,能够与Prometheus无缝集成,提供完美的数据展示
- Alertmanager:用户可以定义基于监控数据的告警规则,规则会触发告警。一旦Alertmanager收到告警,会通过预定义的方式高级功能通知。支持Email、PagerDuty、Webhook
Prometheus Operator架构
Prometheus Operator的目标是尽可能简化在k8s中部署和维护Prometheus的工作

- Operator:Operator即Prometheus Operator,在k8s中以Deployment运行。其职责是部署和管理Prometheus Server,根据ServiceMonitor动态更新Prometheus Server的监控对象
- Prometheus Server:Prometheus Server会作为K8s应用部署到集群中,为了更好的在k8s中管理Prometheus,CoreOS的开发人员专门定义了一个命名为
Prometheus类型的k8s定制化资源,我们可以把Prometheus看做是一种特殊的Deployment,它的用途就是专门部署PrometheusServer - Service:这里的Service就是Cluster中的service资源,也是Prometheus要监控的对象,在Prometheus中叫做Target。每个监控对象都有一个对应的Service。比如要监控
kubernetes scheduler,就有一个与Scheduler对应的Service。由Prometheus Operator负责创建 - ServiceMonitor:Operator能够动态更新Prometheus的Target列表,ServiceMonitor就是Target的抽象。比如监控K8s Scheduler,用户可以创建一个与Scheduler Service相映射的ServiceMonitor对象。Operator则会发现新的ServiceMonitor,并将Scheduler的Target提阿南爱到Prometheus的监控列表中(ServiceMonitor也是PrometheusOperator专门开发的一种Kubernetes定制化资源类型)
- Alertmanager:也是Operator开发的第三种kubernetes定制化资源,用途就是专门部署Alertmanager组件
获取资源

这个heapster在v1.12版本已经被移除,可以通过安装metrice-server来获取这个命令,也可以通过helm安装Prometheus来安装这个服务
相关地址信息
Prometheus GitHub 地址: https://github.com/coreos/kube-prometheus
组件说明
- 1 MetricServer:是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如kubectl、HPA、scheduler等
- 2 PrometheusOperator:是一个系统检测和警报工具箱,用来存储监控数据
- 3 NodeExporter:用于各个node的关键度量指标状态数据
- 4 KubeStateMetrics:手机kubernetes集群内资源对象数据,指定告警规则
- 5 Prometheus:采用pull方式手机apiserver、scheduler、controller-manager、kubelet组件数据,通过http协议传输
- 6 Grafana:是可视化数据统计和监控平台
构建记录
从GitHub上下载Prometheus
1 | mkdir prometheus |
修改grafana-service.yaml文件,使用NodePort方式grafana:
1 | vim grafana-service.yaml |
修改prometheus-service.yaml,改为NodePort
1 | vim prometheus-service.yaml |
修改alertmanager-service.yaml,改为NodePort
1 | vim alertmanager-service.yaml |
安装
1 | kubectl apply -f ../manifests/setup/ |
查看
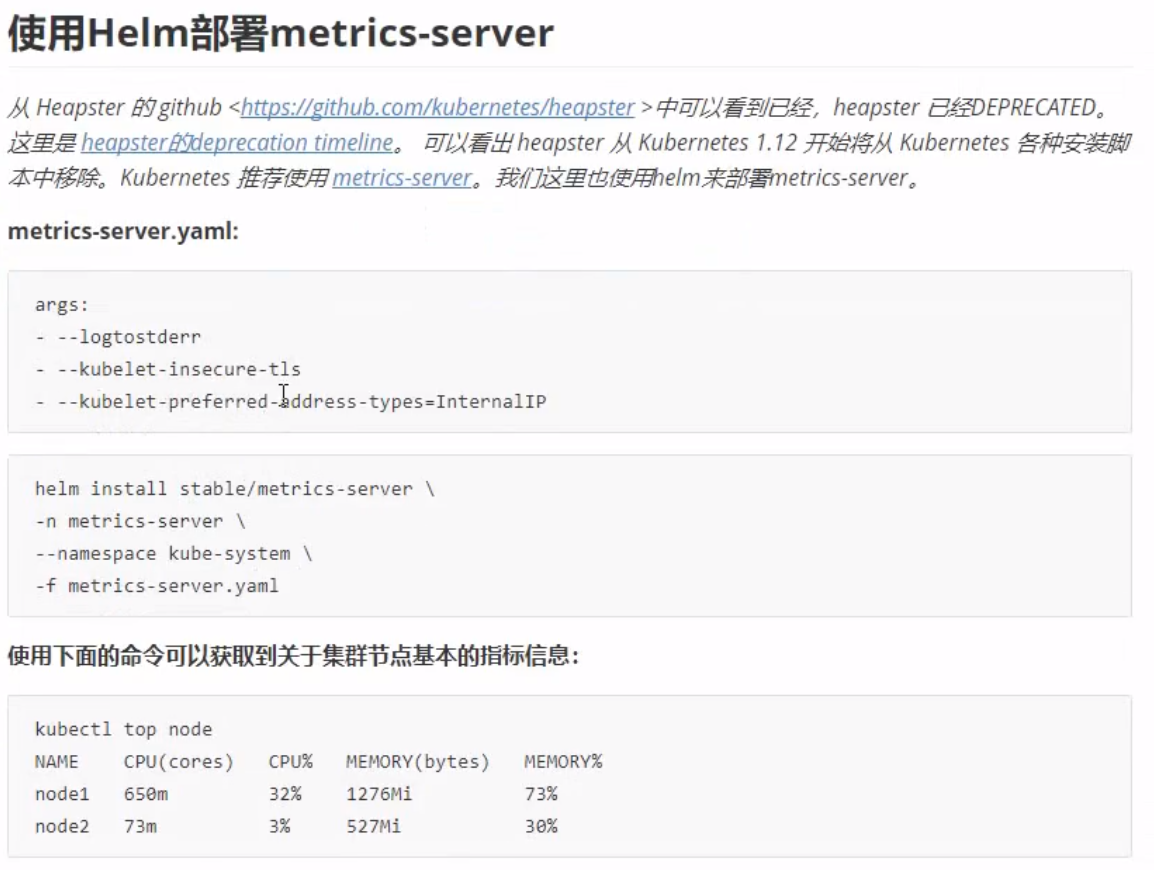
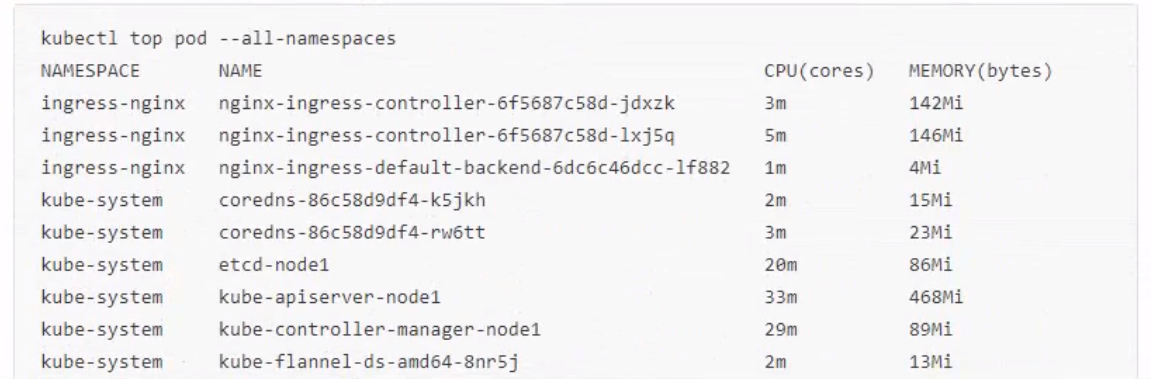
1 | [root@k8s-master manifests]# kubectl get pods -n monitoring |
访问Prometheus
浏览器访问
prometheus对应的NodePort端口为30200,访问http://masterIP:30200**
查看状态
实例
prometheus的web提供了基本的查询k8s集群中每个pod的CPU的情况,查询条件如下
1 | sum by (pod_name)( rate(container_cpu_usage_seconds_total{image!="",pod_name!=""}[1m])) |
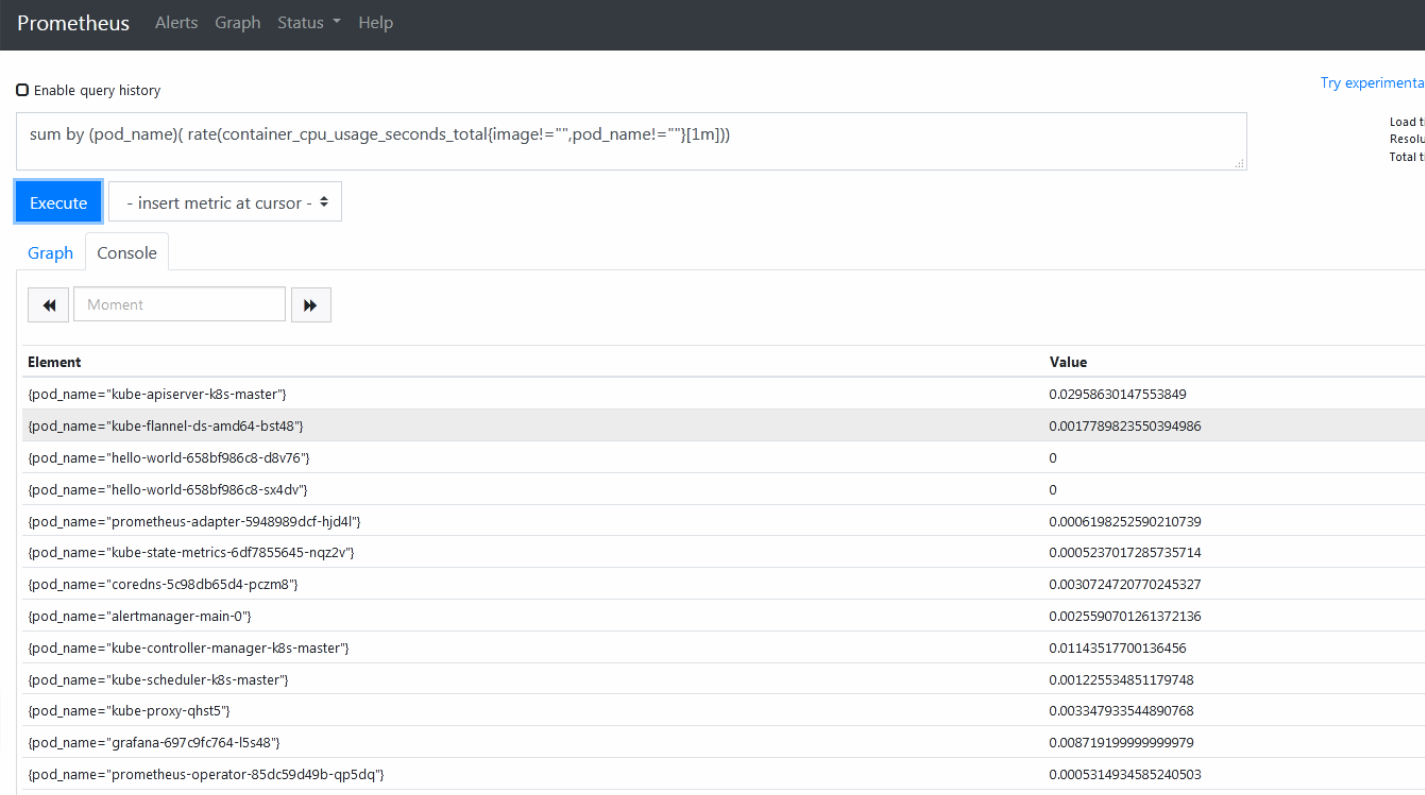
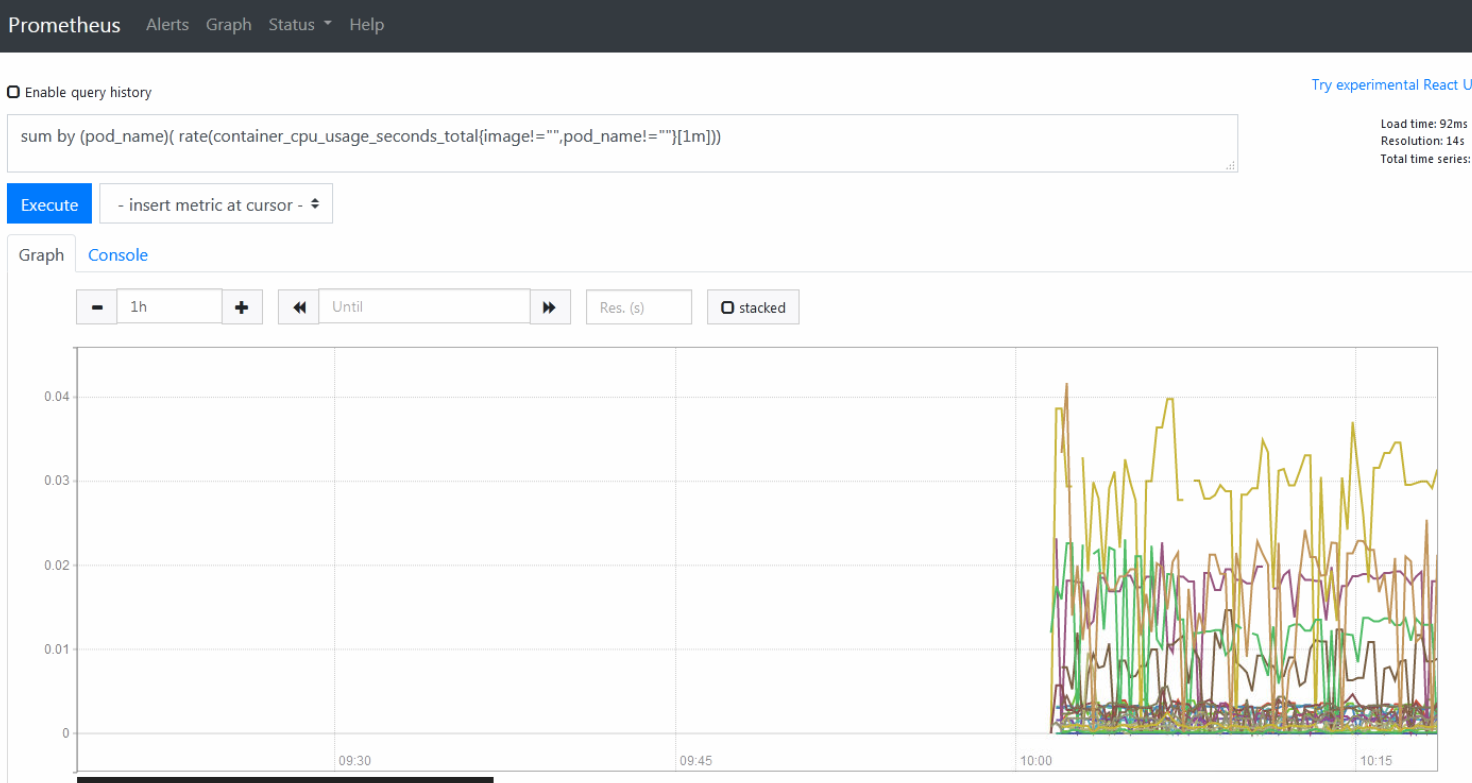
上述的查询有出现数据,说明node-exporter往Prometheus中写入数据正常,接下来我们就可以部署访问grafana组件,实现更友好的WebUI展示数据
访问Grafana
浏览器访问
默认用户名密码:admin/admin

修改默认密码

添加数据来源
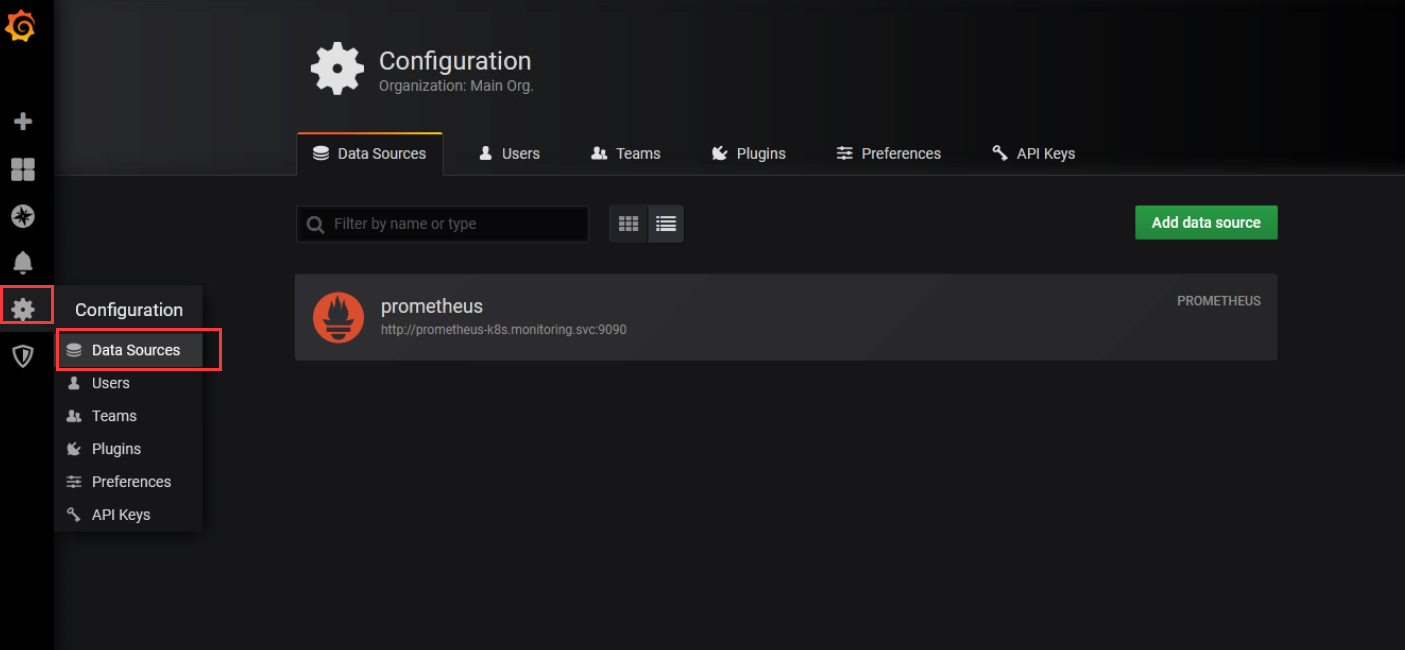
默认已经添加好,点击进入,测试
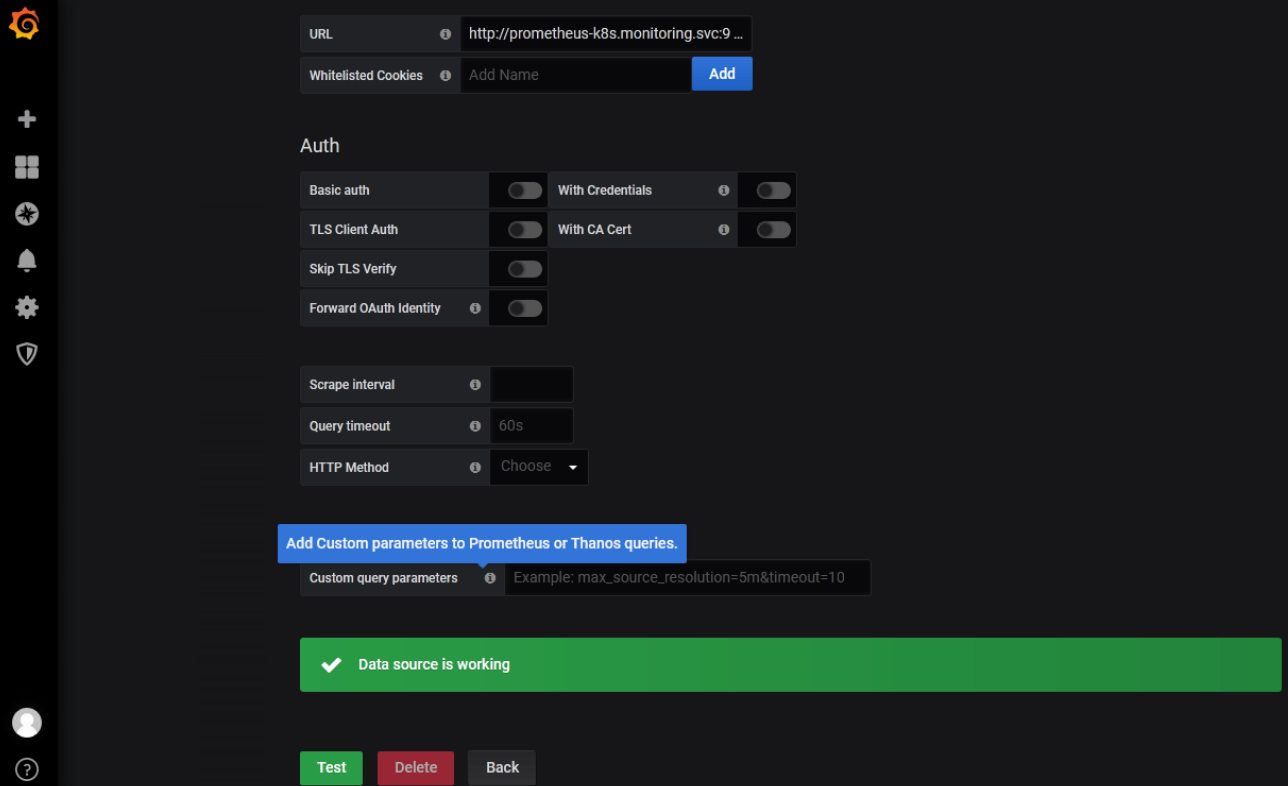
dashboard导入模板
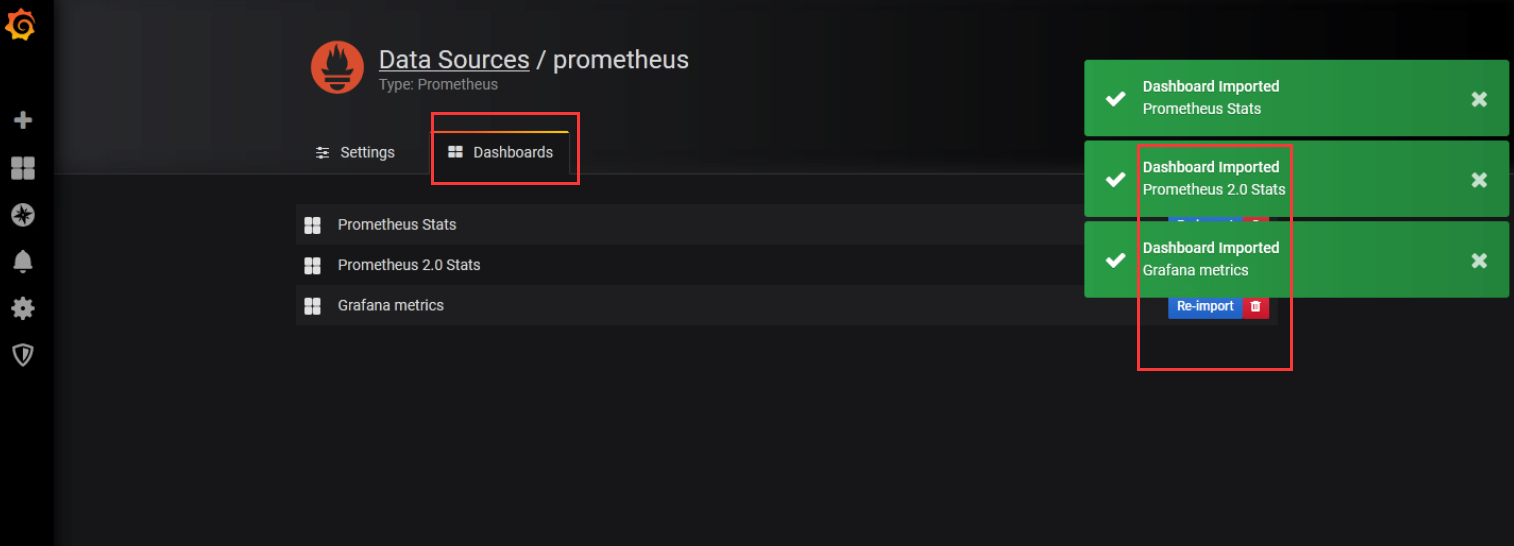
查看数据
进home,点击左上角
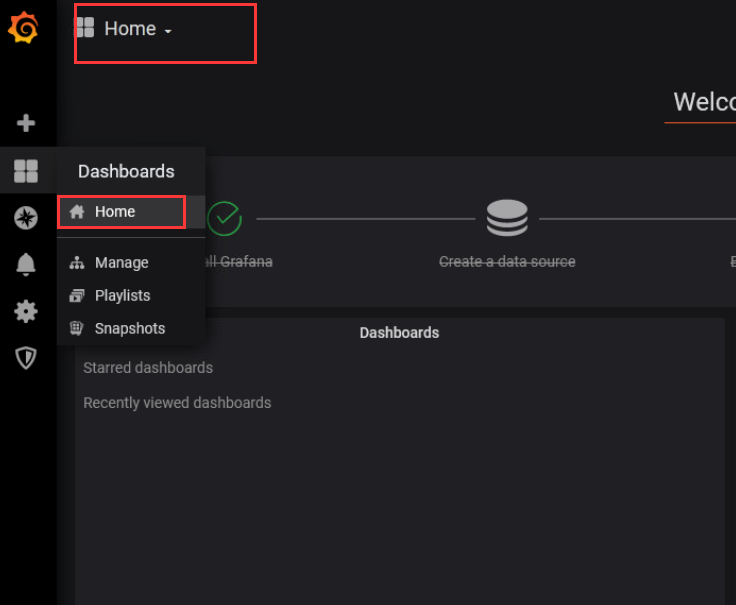
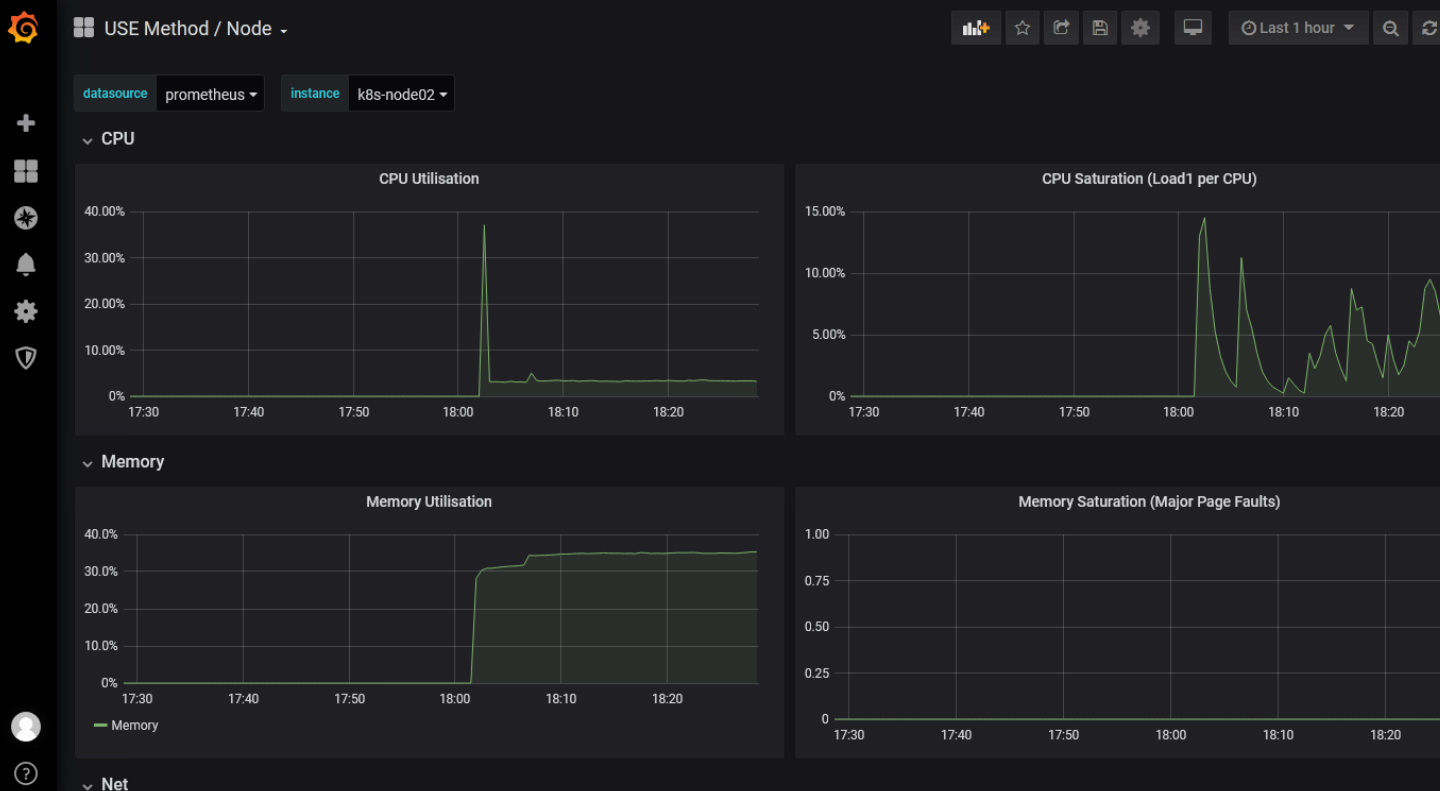
查看node数据

可以看到node资源使用情况
单独安装metrics-server
metrics-server和Prometheus只能安装一个,metrics-server没有界面