原理 随着访问量的不断增加,单台MySQL数据库服务器压力不断增加,需要对MySQL进行优化和架构改造,如果MySQL优化不能明显改善压力,可使用高可用、主从复制、读写分离来拆分库和表等方法进行优化
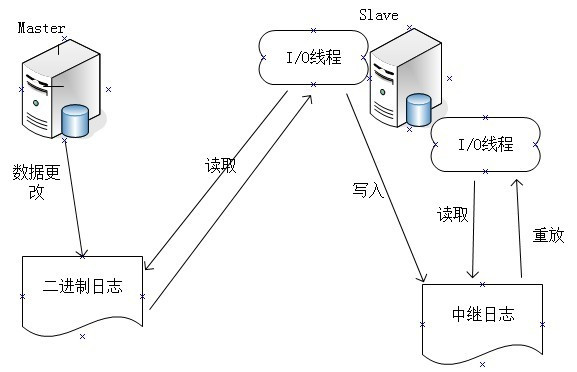
MySQL主从复制集群至少需要2台数据库服务器,其中一台为master,另一台为slave,MySQL主从数据同步是一个异步复制的过程,要实现复制首先需要在master上开启bin-log日志功能,bin-log日志用于记录在master库中执行的增删改操作的SQL语句,整个过程需要开启3个线程,分别是master开启I/O线程,slave开启I/O线程和SQL线程,具体主从同步原理详解如下:
slave上执行slave start,slave I/O线程会通过在master创建的授权用户连接上至master,并请求master从指定的文件和位置之后发送bin-log日志内容
master接收到来自slave I/O线程的请求后,master I/O线程根据slave发送的指定bin-log日志position点之后的内容,然后返回给slave的I/O线程
返回的信息中处理bin-log日志内容外,还有master最新的bin-log文件名以及在bin-log中的下一个指定更新position点
slave I/O线程接收到信息后,将接收到的日志内容依次添加到slave端的relay-log文件的最末端,并将读取到的master端的bin-log的文件名和position点记录到master.info文件中,以便在下一次读取的时候能告知master从响应的bin-log文件名及最后一个position点开始发起请求
slave SQL线程检测到relay-log中内容有更新,会立刻解析relay-log日志中的内容,将解析后的SQL预计在slave里执行,执行成功后slave库与master库则会保持数据一致。实验环境:
master
192.168.5.2
slave
192.168.5.3
主从服务器都已经安装好了mariadb,此方法适用于所有系统,这里我用的是centos7
1 2 3 4 5 6 MariaDB [(none)]> show variables like 'version'; + | Variable_name | Value | + | version | 10.3.8-MariaDB-1:10.3.8+maria~bionic | +
首先在master上的my.cnf的[mysqld]内添加 1 2 3 4 [mysqld] server-id = 1 log-bin = mysql-bin
并重启mysql服务 查看master状态,获取bin-log信息和position点,并授予tongbu用户权限 1 2 3 4 5 6 7 8 9 MariaDB [(none)]> show master status; + | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | + | mysql-bin.000001 | 328 | | | + 1 row in set (0.000 sec) MariaDB [(none )]> grant replication slave on *.* to 'tongbu' @'%' identified by '000000' ; Query OK, 0 rows affected (0.001 sec)
在slave上的my.cnf的[mysqld]内添加 并重启mysql服务 slave指定master的ip,用户名,密码,bing-log,position 1 2 3 4 MariaDB [(none)]> change master to master_host='192.168.5.2',master_user='tongbu',master_password='000000',master_log_file='mysql-bin.000001',master_log_pos=328; Query OK, 0 rows affected (2.485 sec) MariaDB [(none)]> start slave; Query OK, 0 rows affected (0.001 sec)
当出现以下状态则为成功 1 2 3 4 5 MariaDB [(none)]> show slave status\G; … Slave_IO_Running: Yes Slave_SQL_Running: Yes …
验证,在master上创建数据库 1 2 3 4 5 6 7 8 9 10 11 12 MariaDB [(none)]> create database db_test; Query OK, 1 row affected (0.001 sec) MariaDB [(none)]> show databases; + | Database | + | db_test | | information_schema | | mysql | | performance_schema | + 4 rows in set (0.001 sec)
通过查询发现slave也能查到db_test数据库,说明已经成功实现MySQL主从复制 1 2 3 4 5 6 7 8 9 10 MariaDB [(none)]> show databases; + | Database | + | db_test | | information_schema | | mysql | | performance_schema | + 4 rows in set (0.001 sec)
MySQL主从同步排错思路 MySQL主从同步集群在生产环境使用时,如果主从服务器之间网络通信条件差或者数据库数据量非常大,容易导致MySQL主从同步延迟
忽略错误后,继续同步
1 MariaDB [(none)]> flush tables with read lock;
slave端停止slave I/O及 SQL线程,同时将同步错误的SQL跳过一次,跳过错误会导致数据补一次,启动start slave,同步状态恢复,命令如下:
1 2 3 MariaDB [(none)]> stop slave; MariaDB [(none)]> set global sql_slave_skip_counter = 1; MariaDB [(none)]> start slave;
重新做主从同步,使数据完全同步。
1 MariaDB [(none)]> flush tables with read lock;
master端基于mysqldump\xtrabackup工具对数据库进行完整备份,也可以用shell脚本或python脚本实现定时备份,备份成功后,将完整的数据导入至从库,重新配置主从关系,当slave端的I/O线程、SQL线程均为Yes之后,最后将master端读锁解开即可,解锁命令如下:
1 MariaDB [(none)]> unlock tables;